kubectl的top命令与docker的stats命令显示内存不一致问题
kubectl的top命令与docker的stats命令显示内存不一致问题
| 作者 | 王哲 |
|---|---|
| 团队 | Filed&&Suppoort |
| 编写时间 | 2021/5/19 |
| 类型 | 内存相关问题 |
前言
随着云原生技术的逐渐深入和成熟,监控对于平台运维或者业务运维来说都是至关重要的一个话题。相较于过去传统的监控手段和技术,其实云原生在监控方式和角度上都存在不可忽视的差异和变化。本篇文章就是从基础概念结合官方说明以及在日常工作上遇到的一些问题来对容器中的内存监控做一点梳理和总结。
cgroup
提到容器资源,有一个绕不开的linux基础概念就是cgroup,这是Linux内核提供的一种可以限制单个进程或者多个进程所使用资源的机制,是为容器提供资源限制能力的最根本的技术来源。当我们要去获取容器资源使用情况的时候,cgroup文件中的值才是监控数据的最终来源。因此在了解容器资源使用之前我们就应当先了解linux操作系统中cgroup文件中关于资源的相关数据的含义是什么。一般情况下,cgroup文件夹下的内容包括CPU、内存、磁盘、网络等信息:
cgroup目录下常用文件的含义
| 文件名 | 含义 |
|---|---|
| devices | 设备控制权限 |
| cpuset | 分配指定的CPU和内存节点 |
| cpuacct | 控制CPU占用率 |
| memory | 限制内存使用上限 |
| freezer | 冻结(暂停)cgroup中的进程 |
| net_cls | 配合tc限制网络带宽 |
| net_prio | 设置进程的网络流量优先级 |
| hugetlb | 限制HugeTlb的使用 |
| perf_event | 允许perf工具基于cgroup分组做性能检查 |
例如memory目录下常用文件的含义
| 文件名 | 含义 |
|---|---|
| memory.usage_in_bytes | 已使用的内存量(包含cache和buffer)单位字节 |
| memory.limit_in_bytes | 限制内存的总量 |
| memory.failcnt | 申请内存失败计数次数 |
| memory.memsw.usage_in_bytes | 已使用的内存和swap |
| memory.memsw.limit_in_bytes | 限制内存和swap |
| memory.memsw.failcnt | 申请内存和swap失败次数计数 |
| memory.stat | 内存使用相关参数的集合 |
展开描述memory.stat文件中的信息
| 参数名 | 含义 |
|---|---|
| cache | 页缓存,包括tmfs(shmem),单位字节 |
| rss | 匿名和swap缓存,但不包括tmfs,单位字节 |
| mapped_file | 映射文件大小,包括tmfs,单位字节 |
| swap | swap用量 |
| pgpgin | 存入内存中的页数 |
| pgpgout | 从内存中读出的页数 |
| inactive_anon | 不活跃的LRU列表中的匿名和swap缓存,包括tmps(shmem),单位字节 |
| active_anon | 在活跃的最近最少使用LRU列表中的匿名和swap缓存,包括tmps,单位是字节 |
| inactive_file | 不活跃LRU列表中的file-backed内存,以字节为单位 |
| active_file | 活跃LRU列表中的file-backed内存,以字节为单位 |
| unevictable | 无法再生的内存,以字节为单位 |
| hierarchical_memory_limit | 包含memeory cgroup 的层级的内存限制,单位为字节 |
| hierarchical_memsw_limit | 包含memory cgroupd的层级的内存加swap限制,单位为字节 |
另外这个文件中关于内存的信息是最全的
以上提供了这么多的文件和参数含义,其实是为了更好的去理解在我们容器监控中使用的一些数据来源和表达式,例如在获取容器内存使用量其实就是存储在/sys/fs/cgroup/memory/docker/<containerId>/memory.usage_in_bytes 文件内,再例如容器内存限制问题,如果没限制内存,Limit = machine_mem,否则该限制数值来自于/sys/fs/cgroup/memory/docker/[id]/memory.limit_in_bytes。
kubectl top监控原理
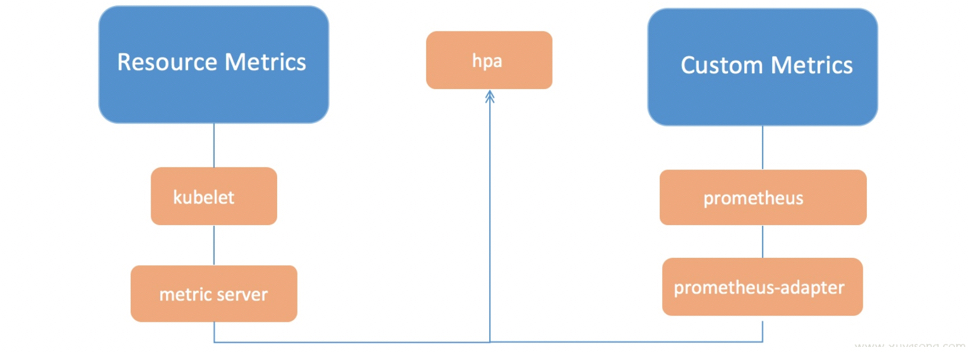
数据链路
kubectl top和k8s dashboard以及HPA等调度组件使用的数据是一样,数据链路如下:

使用metrics-server时apiserver是通过/apis/metrics.k8s.io/的地址访问metric
metric-server和普通pod都是使用 api/xx 的资源接口,即 metric作为一种资源存在,如metrics.k8s.io 的形式,称之为 Metric Api,用于从kubelet获取指标。
监控体系
在提出 metric api 的概念时,官方页提出了新的监控体系,监控资源被分为了2种:
- Core metrics(核心指标):从 Kubelet、cAdvisor 等获取度量数据,再由metrics-server提供给 Dashboard、HPA 控制器等使用。
- Custom Metrics(自定义指标):由Prometheus Adapter提供API custom.metrics.k8s.io,由此可支持任意Prometheus采集到的指标。
核心指标只包含node和pod的cpu、内存等,一般来说,核心指标作HPA已经足够,但如果想根据自定义指标:如请求qps/5xx错误数来实现HPA,就需要使用自定义指标了。
目前Kubernetes中自定义指标一般由Prometheus来提供,再利用k8s-prometheus-adpater聚合到apiserver,实现和核心指标(metric-server)同样的效果。
kubectl top与docker stats内存不一致问题
参数解释
| 名称 | 说明 |
|---|---|
| container_memory_rss | RSS内存,即常驻内存集(Resident Set Size),是分配给进程使用实际物理内存,而不是磁盘上缓存的虚拟内存。RSS内存包括所有分配的栈内存和堆内存,以及加载到物理内存中的共享库占用的内存空间,但不包括进入交换分区的内存。 |
| container_memory_usage_bytes | 当前使用的内存量,包括所有使用的内存,不管有没有被访问。 |
| container_memory_max_usage_bytes | 最大内存使用量的记录 |
| container_memory_cache | 高速缓存(cache)的使用量。cache是位于CPU与主内存间的一种容量较小但速度很高的存储器,是为了提高cpu和内存之间的数据交换速度而设计的 Size),是分配给进程使用实际物理内存,而不是磁盘上缓存的虚拟内存。RSS内存包括所有分配的栈内存和堆内存,以及加载到物理内存中的共享库占用的内存空间,但不包括进入交换分区的内存。 |
| container_memory_swap | 虚拟内存使用量。虚拟内存(swap)指的是用磁盘来模拟内存使用。当物理内存快要使用完或者达到一定比例,就可以把部分不用的内存数据交换到硬盘保存,需要使用时再调入物理内存 |
| container_memory_working_set_bytes | 当前内存工作集(working set)使用量,是容器真实使用的内存量 |
| container_memory_failcnt | 申请内存失败次数计数 |
| container_memory_failures_total | 累计的内存申请错误次数 |
三个内存计算公式:
- container_memory_working_set_bytes = container_memory_usage_bytes - total_inactive_anon - total_inactive_file
- memory used =container_memory_usage_bytes - cache
- cache = total_inactive_file + total_active_file
kubectl top 与 docker status的计算方式:
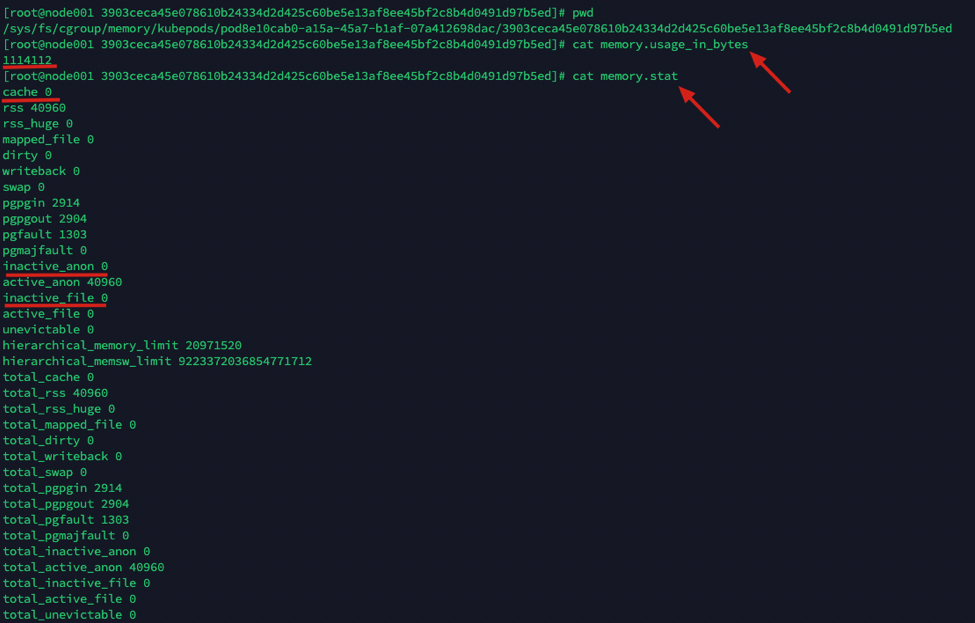
- 使用kubectl top(container_memory_working_set_bytes) = memory.usage_in_bytes - inactive_file
- 使用docker stats(memory used) = memory.usage_in_bytes - cache
kubelet oom kill 的依据:
kubelet比较container_memory_working_set_bytes和container_spec_memory_limit_bytes来决定oom container
Java应用的内存读取机制和oom kill依据(8u以下版本)
- java不支持读取cgroup的限制。 默认是从/proc/目录读取可用内存。但是容器中的/proc目录默认是挂载的宿主机的内存目录。即java 读取的到可用的内存是宿主机的内存。那么自然会导致进程超出容器limit 限制的问题。
- java是根据jvm中-Xmx的参数设置来限制进程的最大堆内存,这样的话java 去oom kill只会判断该进程资源使用是否超过限制。
假设:
例如:容器的limit限制为4G。 那么设置java进程的最大堆内存为3.5G,采用这种方式后,容器重启的情况会少很多,但还是偶尔会出现OOMKilled 的情况。因为-xms 只能设置java进程的堆内存。 但是其他非堆内存的占用一旦超过预留的内存。还是会被kubernetes kil掉。 出现这样的本质原因还是因为oom kill的主体不同角度不同。
是否有解决办法?
- 升级java版本。Java 10支持开箱即用的容器,它将查找linux cgroup信息。这允许JVM基于容器限制进行垃圾收集。默认情况下使用标志打开它。
其中一些功能已被移植到8u131和9以后。可以使用以下标志打开它们。
- LXCFS,FUSE filesystem for LXC是一个常驻服务,它启动以后会在指定目录中自行维护与上面列出的/proc目录中的文件同名的文件,容器从lxcfs维护的/proc文件中读取数据时,得到的是容器的状态数据,而不是整个宿主机的状态。 这样。java进程读取到的就是容器的limit 限制。而不是宿主机内存
- -XX:MaxRAM=
cat /sys/fs/cgroup/memory/memory.limit_in_bytes通过MaxRAM 参数读取默认的limit限制作为java 内存的最大可用内存。同时结合-Xmx 设置堆内存大小
(以上仅供参考,未落地实践!!!)
总结一下
由于total_inactive_anon、total_inactive_file为非活动内存,可以被交换到磁盘 cache 缓存存储器存储当前保存在内存中的磁盘数据,所以站在容器的角度判断container_memory_working_set_bytes会比container_memory_usage_bytes更为准确。
如果单从一个java进程的使用情况就来判断一个java容器的资源使用情况,未免有些以偏盖全。我们应当从过去进程的视角做出转变放大来看整个容器或者说一个容器的全生命周期,这样的话当我们从容器的角度再看资源使用情况,就能统揽全局。